![]() English translation of this paper
English translation of this paper ![]() Remko
Scha
Remko
Scha
In: R. de Kort and G.L.J. Leerdam (red.): Computertoepassingen in de Neerlandistiek. Almere: LVVN, 1990, pp. 7-22.
Remko Scha
Institute for Logic, Language and Computation
Universiteit van AmsterdamTaaltheorie en taaltechnologie;
competence en performance.
Samenvatting.
De huidige generatie van taalverwerkingssystemen is gebaseerd op linguïstisch gemotiveerde competence-modellen van natuurlijke talen. De problemen die optreden met deze systemen suggereren de noodzaak van meer performance-georiënteerde taalverwerkingsmodellen, die rekening houden met de statistische eigenschappen van het feitelijk taalgebruik. Dit artikel formuleert de globale opzet van zo'n performance-model. Het voorgestelde systeem maakt gebruik van een geannoteerd corpus; bij het analyseren van nieuwe invoer probeert het de meest waarschijnlijke manier te vinden om deze invoer te rekonstrueren uit brokstukken die reeds in het corpus aanwezig zijn. Dit perspektief op taalverwerking blijkt ook belangwekkende konsekwenties te hebben voor de taalkundige theorie; enkele daarvan worden kort besproken.
1. Inleiding.
Uitgangspunt voor dit artikel was de vraag: wat kan de taaltechnologie betekenen voor de taaltheorie? Het gebruikelijke antwoord daarop luidt, dat de toepassing van de methoden en inzichten van de theoretische taalkunde in werkende computer-programma's een goede manier is om de theoretische ideeën te toetsen en te verfijnen. Ik vind dat een korrekt antwoord, en ik zal het hier ook weer eens, met enige nadruk zelfs, naar voren brengen. Maar het grootste deel van dit artikel is gewijd aan een wat spekulatievere gedachtengang, die laat zien dat taaltechnologische overwegingen belangrijke theoretische implikaties kunnen hebben.
Centraal in mijn beschouwing staat een fundamenteel probleem dat zich voordoet bij de huidige taalverwerkende systemen: het probleem van de ambiguïteit. Om het ambiguïteitsprobleem op te lossen is het nodig, linguïstische inzichten over struktuur en betekenis van taal-uitingen onder één noemer te brengen met statistische gegevens over feitelijk taalgebruik. Ik zal een techniek schetsen die dat zou kunnen doen: data-georiënteerde parsering, door middel van pattern-matching met een geannoteerd corpus. Deze parseertechniek is wellicht van meer dan technologisch belang: hij suggereert een nieuw perspektief op taal en taalvermogen, dat aantrekkelijke eigenschappen heeft.
Nog een waarschuwend woord vooraf. De hier volgende beschouwingen koncentreren zich vrijwel volledig op het probleem van de syntaktische analyse. Natuurlijk is dat slechts een deelprobleem -- zowel in de taaltheorie als in de taaltechnologie. Dit probleem blijkt echter op zichzelf reeds zoveel stof tot nadenken op te leveren, dat het niet nuttig lijkt, de diskussie verder te kompliceren door de integratie met fonetiek, fonologie, morfologie, semantiek, pragmatiek, en discourse-processing aan de orde te stellen. Hoe de verschillende soorten linguïstische kennis in een taalverwerkend systeem over de modules van het taalverwerkings-algoritme verdeeld moeten zijn, is een vraag die volledig buiten beschouwing blijft.
2. Inleiding: taalwetenschap en computerlinguistiek.
Om de taalkunde tot een strenge wetenschap te kunnen maken, heeft Chomsky [1957] het intuïtieve idee van een "taal" voorzien van een mathematisch correlaat. Hij stelde voor om een taal te vereenzelvigen met een verzameling zinnen: met de verzameling van de grammatikaal korrekte uitingen die in de taal mogelijk zijn. Het doel van de deskriptieve taalkunde is dan, om voor individuele talen de verzameling van grammatikale zinnen expliciet te karakteriseren, door middel van een formele grammatika. En het doel van verklarende taalkundige theorieën moet dan zijn, om de universele eigenschappen te bepalen die de grammatika's van alle talen met elkaar gemeen hebben, en om die universalia psychologisch te verantwoorden.
In deze opvatting houdt de taalwetenschap zich dus niet onmiddellijk bezig met de beschrijving van het feitelijke taalgebruik in een taalgemeenschap. Hoewel we mogen aannemen dat er 'n relatie bestaat tussen de grammatikaliteitsintuïties van de taalgebruikers en hun aktuele taalgedrag, moeten we die twee toch scherp onderscheiden: enerzijds biedt het systeem van een taal wellicht mogelijkheden die zelden of nooit gebruikt worden; anderzijds komen er in het feitelijk taalgebruik vergissingen en onnauwkeurigheden voor die een taalkundige theorie niet noodzakelijkerwijs hoeft te verantwoorden. In Chomsky's terminologie: de taalwetenschap houdt zich bezig met de taalkundige competentie van de taalgebruiker, en niet met diens feitelijke performance. Of, in de woorden van Saussure, die dit onderscheid reeds eerder benadrukt had: wel met de langue, niet met de parole.
Chomsky's werk is het methodologisch paradigma geweest voor vrijwel alle taalkundige theorie van de laatste decennia. Dat geldt niet alleen voor de onderzoekstraditie die zich expliciet tot doel stelt om Chomsky's syntaktische inzichten uit te werken. Het hierboven samengevatte perspektief heeft eveneens de doelstellingen en werkwijzen bepaald van de belangrijkste alternatieve benaderingen van syntax, en van de semantische onderzoekstradities die uit het werk van Richard Montague voortgekomen zijn. Hoe verhoudt de taaltechnologie zich nu tot dit taaltheoretisch paradigma?
Slechts een minderheid onder de taaltechnologen beroept zich expliciet op Chomsky's ideeën; maar de methodologische aannames van taaltechnologische onderzoeksinspanningen komen toch meestal, zij het impliciet, voort uit hetzelfde paradigma. Vanzelfsprekend zijn er ook belangrijke verschillen tussen het theoretisch georiënteerde en het technologisch georiënteerde taal-onderzoek. Vergeleken met de theoretische taalwetenschap is het taaltechnologisch onderzoek meestal deskriptiever van aard geweest, en minder bekommerd om de algemeen-geldigheid en de verklarende kracht van de theorie. Bij het ontwikkelen van een vertaalsysteem of een natuurlijke-taal database-interface heeft de deskriptieve adekwaatheid van de grammatika van de invoertaal nu eenmaal een hogere prioriteit dan het verkrijgen van inzichten over syntaktische universalia. Even voor de hand liggend is de observatie, dat de syntaktische en semantische regels die ontwikkeld worden ten behoeve van een taaltechnologische toepassing, strikt formeel uitgewerkt moeten zijn, terwijl men in het theoretisch onderzoek nog wel eens kan volstaan met essayistische beschouwingen over diverse varianten van een informeel gepresenteerd idee.
We zien aldus een complementaire relatie tussen de theoretische taalwetenschap en de taaltechnologie: in de theorie houdt men zich, op een veelal informele manier, bezig met de algemene struktuur van de taalkundige competentie en met de Universele Grammatika; in de taaltechnologie probeert men, in volledig formeel detail, deskriptief adekwate grammatika's van individuele talen te specificeren. Dit betekent dat taaltechnologisch werk uiteindelijk een aanzienlijk theoretisch belang zal hebben: de theoretische spekulaties over de struktuur van de taalkundige competentie kunnen slechts gevalideerd worden als ze leiden tot een formeel kader waarin deskriptief adekwate grammatika's gespecificeerd kunnen worden. Omdat men zich in de theoretische taalwetenschap niet zo voor deze randvoorwaarde lijkt te interesseren, vormen de toepassings-gerichte aktiviteiten op grammatika-gebied een nuttige en noodzakelijke aanvulling op het taaltheoretisch onderzoek.
Uit het taaltechnologisch werk is inmiddels wel gebleken dat computer-ondersteuning in elk geval nodig is bij de ontwikkeling van theoretisch interessante grammatika's. Formele grammatika's die enkele non-triviale verschijnselen gedeeltelijk korrekt beschrijven zijn al gauw uiterst complex -- zo complex, dat het niet goed voorstelbaar is hoe men ze zonder computationele hulpmiddelen zou kunnen testen, onderhouden en uitbreiden.
De taaltechnologie is om nog een andere reden interessant voor de taaltheorie: in taaltechnologische toepassingen gaat het om systemen die dienen om gebruikt te worden met een of andere vorm van "echte taal" als invoer. Dit betekent dat de implementatie van een competentie-grammatika uiteindelijk niet voldoende zal zijn: er zal ook programmatuur ontwikkeld moeten worden die met eventuele relevante performance-verschijnselen omgaat, en die zal op een adekwate manier met de competentie-grammatika moeten interfacen. De mogelijkheid om een competentie-grammatika te complementeren met een verantwoording van performance-verschijnselen is een andere randvoorwaarde van de huidige taalkundige theorie die in het theoretisch onderzoek niet veel systematische aandacht krijgt. Ook hier kunnen we aan het taaltechnologisch onderzoek een rol van theoretisch belang toekennen.
Er zijn dus mogelijkheden te over voor interessante interakties tussen taaltheorie en taaltechnologie; maar die werden tot voor kort nog niet vaak gerealiseerd. Lange tijd heeft de taaltechnologie zich nogal geïsoleerd van de theoretische taalwetenschap ontwikkeld. Dit isolement is ontstaan doordat Chomsky's formulering van zijn syntaktische inzichten steeds cruciaal gebruikt maakte van de notie van "transformatie" -- een notie die, met name voor analyserende algoritmes, door velen als computationeel onaantrekkelijk werd ervaren. Computerlinguïsten voelden zich genoodzaakt om alternatieve methoden voor taalbeschrijving te ontwikkelen die rechtstreekser gekoppeld waren aan lokaal observeerbare eigenschappen van de opppervlaktestruktuur, en om die reden makkelijker implementeerbaar; zo ontstonden Augmented Transition Networks en verrijkte kontekstvrije grammatika's. Sinds de hoogtijdagen van de Transformationele Grammatika verstreken zijn, is er echter een opmerkelijke toenadering geweest tussen de taaltheorie en de taaltechnologie, doordat de verrijkte kontekstvrije grammatika's, die computationeel wel aantrekkelijk gevonden worden, theoretische respektabiliteit gekregen hebben. De Generalized Phrase Structure Grammar campagne van Gazdar, Pullum en Sag heeft op dit punt voor een doorbraak gezorgd.
Voor verrijkte kontekstvrije grammatika's zijn effektieve parseer-algoritmen ontwikkeld. Er zijn procedures die op een redelijk efficiënte wijze de grammatikaliteit van een willekeurige input-zin vaststellen, en er de struktuurbeschrijving(-en) aan toekennen zoals door de grammatika gedefinieerd. Dit heeft het mogelijk gemaakt om interessante prototype-systemen te implementeren die hun invoer analyseren volgens zo'n grammatika. De resultaten van deze aanpak zijn bemoedigend geweest. Ze waren zeker beter dan die van de konkurrerende benaderingen uit de Artificiële Intelligentie, die geprobeerd hebben om het zonder formele syntax te stellen (zoals de prototypische varianten van "frame-based parsing" en van "neurale netwerken"). Toch is de praktische toepassing van linguïstische grammatika's in taalverwerkingssystemen niet zonder problemen. Die bezien we in de volgende sektie.
3. Beperkingen van de huidige taalverwerkingssystemen.
De toepasbaarheid van de nu bestaande linguïstische technologie is uiteraard afhankelijk van de beschikbaarheid van deskriptief adekwate grammatika's voor substantiële fragmenten van natuurlijke talen. Maar het schrijven van een stelsel regels dat de grammatikale strukturen van een natuurlijke taal goed karakteriseert blijkt verrassend moeilijk. Er bestaat nog geen enkele formele grammatika die de rijkdom van een natuurlijke taal korrekt beschrijft -- zelfs geen enkele formele grammatika die een non-triviaal corpus van enige omvang goed "overdekt". Het probleem is niet alleen dat de syntax van natuurlijke taal omvangrijk en ingewikkeld is, en dat er dus nog hard doorgewerkt en diep nagedacht zal moeten worden. Het proces van het ontwikkelen van een formele grammatika van een gegeven natuurlijke taal is vooral teleurstellend omdat het moeizamer gaat naarmate de grammatika groter wordt. Hoe meer verschijnselen er reeds ten naasten bij verantwoord worden, des te meer interakties moeten er bekeken worden als men een verantwoording van nieuwe verschijnselen probeert te introduceren.
Een tweede probleem met het huidige syntax/parserings-paradigma is nog makkelijker waar te nemen: het probleem van de ambiguïteit. Het is gebleken dat zodra een grammatika een non-triviaal gedeelte van een natuurlijke taal karakteriseert, vrijwel elke input-zin van enige lengte veel (vaak zeer veel) verschillende strukturele analyses (en bijbehorende semantische interpretaties) heeft. Dit is problematisch omdat meestal het meerendeel van deze interpretaties door een menselijke taalgebruiker helemaal niet als mogelijk wordt waargenomen, terwijl er toch geen reden valt te bedenken om ze op formele syntaktische of semantische gronden uit te sluiten. Vaak is het slechts een kwestie van relatieve implausibiliteit: de enige reden waarom de taalgebruiker een bepaalde interpretatie van een zin niet gewaar wordt, is dat een andere interpretatie veel plausibeler is.
De beide genoemde problemen zijn niet onafhankelijk van elkaar. Het eerstgenoemde probleem, de verontrustende kombinatoriek van interagerende syntaktische verschijnselen, heeft tot gevolg dat we de verfijning van syntaktische subcategorieën misschien wat zouden willen beperken, met als gevolg een "tolerantere" grammatika die allerlei minder gelukkige konstrukties toch als grammatikaal accepteert. Dit is een mogelijke strategie, omdat het Chomskyaanse paradigma niet duidelijk vastlegt hoe de taalkundige "competence" ten opzichte van de "performance" gedelimiteerd moet worden. Niet alle beoordelingen van zinnen als "raar", "ongewoon", "ongelukkig", "inkorrekt", of "oninterpreteerbaar" hoeven als negatieve grammatikaliteitsoordelen gezien te worden; uiteindelijk bepaalt de elegantie van de resulterende theorie of bepaalde onwelgevormdheids-oordelen door de competentie-grammatika dan wel door de performance-module verantwoord dienen te worden. Maar wie taalverwerkende systemen wil maken is daarmee niet klaar: die wordt gekonfronteerd met een nog grotere ambiguïteit in de output van de grammatikale analyse, en moet onder ogen zien hoe een performance-module daar een zinnige selektie uit maakt.
4. Competence en Performance.
In zekere zin zijn de beperkingen van de huidige taalverwerkingssystemen niet verrassend: ze zijn een onmiddellijk gevolg van het feit dat deze systemen heel direkt aansluiten bij Chomsky's notie van een competence-grammatika. Chomsky heeft altijd een heel nadrukkelijk onderscheid gemaakt tussen de "competentie" van de taalgebruiker en de "performance" van deze taalgebruiker. De competentie is de taalkennis waarover de taalgebruiker in principe beschikt; de performance is het resultaat van het psychologisch proces dat die kennis gebruikt (zowel producerend als interpreterend). De formele grammatika's die het onderwerp vormen van de theoretische linguistiek, hebben tot doel om de competentie van de taalgebruiker te karakteriseren. Maar de voorkeuren die taalgebruikers hebben in het geval van syntaktisch meerduidige zinnen, behoren nu typisch tot het domein dat in een Chomskyaanse optiek tot de performance zou worden gerekend.
Het genoemde ambiguïteitsprobleem is een gevolg van een intrinsieke beperking van de linguïstische competentie-grammatika's: ze geven een definitie van de zinnen van een taal en de bijbehorende strukturele analyses, maar ze specificeren geen waarschijnlijkheidsordening of andere "ranking" tussen de verschillende zinnen of tussen de verschillende analyses van een zin. Deze beperking heeft nog ernstiger gevolgen wanneer een grammatika gebruikt wordt bij het verwerken van input waarin frequent fouten optreden. Zo'n situatie doet zich voor bij de verwerking van gesproken taal. De output van een spraakherkenningssysteem is altijd zeer onvolmaakt, omdat zo'n systeem vaak slechts gissingen doet naar de identiteit van zijn input-woorden. In die situatie heeft het parseermechanisme nog een extra taak, die het bij korrekt getypte alfa-numerieke invoer niet heeft. De spraakherkenningsmodule kan vele verschillende woordsequenties menen te horen in het input-signaal; slechts één daarvan is de juiste, en de parseer-module moet zijn syntaktische informatie gebruiken om tot een optimale beslissing te komen over de aard van de input. Een eenvoudig ja/nee oordeel over de grammatikaliteit van een woord-sequentie is daarbij onvoldoende: veel woord-sequenties zijn strikt genomen grammatikaal maar erg onplausibel; en naarmate een grammatika meer verschijnselen verantwoordt, wordt dit aantal groter.
Om effektieve taalverwerkingssystemen te konstrueren, moeten we ons dus bezig houden met de implementatie van performance-grammatika's in plaats van competentie-grammatika's. Die performance-grammatika's moeten dan niet alleen informatie bevatten over de strukturele mogelijkheden van het algemene taalsysteem, maar ook over "toevallige" details van het aktuele taalgebruik in een taalgemeenschap, die bepalend zijn voor de taal-ervaringen van een individu, en die aldus mede bepalen wat voor taaluitingen dit individu verwacht te zullen tegenkomen, en welke strukturen en betekenissen die taaluitingen verwacht worden te hebben.
Impliciet in het linguïstisch denken over performance is de aanname dat het taalgedrag verantwoord kan worden door een systeem dat een competentie-grammatika omvat als een identificeerbare subcomponent. Juist het ambiguïteitsprobleem maakt dit echter tot een computationeel onaantrekkelijke aanname: als we kriteria zouden vinden om sommige syntaktische analyses boven andere te prefereren, dan kan het de efficiëntie van het geheel ten goede komen als die in een vroegtijdig stadium, geïntegreerd met de strikt syntaktische regels, worden toegepast. Dat zou dan neerkomen op een geïntegreerde implementatie van de competentie- en performance-noties.
Maar we kunnen ook een stap verder gaan, en de gangbare notie van een competentie-grammatika fundamenteel ter diskussie stellen. We kunnen proberen de taal-performance te verantwoorden zonder een beroep te doen op een expliciete competentie-grammatika. (Dat zou dan betekenen dat grammatikaliteitsoordelen verantwoord moeten worden als een performance-verschijnsel dat zich niet door een bijzondere cognitieve status van andere performance-verschijnselen onderscheidt.) Dit is de gedachte die ik nu een ietwat konkrete uitwerking wil geven. Op de mogelijke theoretische merites van dit standpunt kom ik later (in sektie 7) nog terug.
5. Statistiek.
Er bestaat een alternatieve taalbeschrijvingstraditie die zich altijd al op de konkrete details van het feitelijk taalgebruik geconcentreerd heeft, vaak zonder zich veel aan het abstrakte taalsysteem gelegen te laten liggen: de statistische traditie. In deze benadering ziet men vaak volledig af van het karakteriseren van syntaktische strukturen; men beschrijft uitsluitend "oppervlakkige" statistische eigenschappen van een zo groot mogelijk representatief taal-corpus. Meestal geeft men eenvoudigweg de frekwenties van voorkomen van de verschillende woorden, de kans dat een bepaald woord gevolgd wordt door een bepaald ander woord, de kans dat een bepaalde sequentie van 2 woorden gevolgd wordt door een bepaald woord, etc. (ne orde Markov-ketens). Zie b.v.: Bahl et al., 1983; Jelinek, 1986.
Voor het doel van het selekteren van de meest waarschijnlijke zin uit alle outputs van een spraakherkenningskomponent, is de Markov-benadering heel suksesvol geweest. Het zal echter duidelijk zijn dat deze benadering voor allerlei andere doeleinden volledig tekortschiet, omdat er geen notie van syntaktische struktuur gebruikt wordt. Voor een natuurlijke-taal database-interface, b.v., is het nodig dat er semantische interpretatieregels worden toegepast, op basis van een strukturele analyse van de input. Ook zijn er statistische samenhangen in de zinnen van een corpus, die zich via syntaktische strukturen over lange woordsequenties kunnen uitstrekken; die worden in de Markov-benadering dus genegeerd. De uitdaging is nu, om een manier van taalbeschrijving en parsering te ontwikkelen, die recht doet zowel aan de statistische alsook aan de strukturele aspekten van taal.
De gedachte dat een synthese tussen de syntaktische en de statistische benaderingswijzen nuttig en interessant zou zijn is incidenteel wel eens eerder geopperd, maar is tot nog toe nog niet goed doordacht. De enige technische uitwerking die er momenteel van bestaat, de notie van een statistische grammatika, is nogal simplistisch van aard. Zo'n grammatika is eenvoudigweg een juxtapositie van de meest fundamentele syntaktische notie met de meest fundamentele statistische notie: het is een "ouderwetse" contextvrije grammatica, die syntaktische strukturen beschrijft door middel van een stelsel abstrakte herschrijfregels -- herschrijfregels die nu echter voorzien zijn van waarschijnlijkheden of van "rankings" die met de toepassingswaarschijnlijkheden van de betreffende regels correleren. (Derouault en Merialdo, 1986; Fusijaki, 1984; Fusijaki et al., 1989.)
Zolang er in zo'n statistische grammatika uitsluitend waarschijnlijkheden toegekend zijn aan individuele syntaktisch gemotiveerde herschrijfregels, kan de grammatica lang niet alle relevante statistische eigenschappen van een taal-corpus weergeven. Er kan dan bijvoorbeeld niet aangegeven worden hoe de waarschijnlijkheid van voorkomen van syntaktische strukturen of lexikale items afhangt van de syntaktisch/lexikale kontekst. Dat heeft tot gevolg dat het niet eens mogelijk is om veel voorkomende frases en stijlfiguren als zodanig te herkennen -- een teleurstellende eigenschap, want men zou graag zien dat zulke frases en stijlfiguren vanzelf een hoge prioriteit zouden krijgen in de ranking van de verschillende mogelijke syntaktische analyses van een zin.
6. Een nieuwe benadering: data-georiënteerde parsering.
De huidige statistische grammatika's werken met eenheden die te klein zijn: herschrijfregels die precies één niveau van de konstituenten-struktuur van een zin beschrijven, en die verondersteld worden kontekst-onafhankelijke toepassingswaarschijnlijkheden te hebben. In plaats daarvan, zouden we de statistische benadering willen toepassen op grotere eenheden. Er bestaat reeds een taalkundige traditie die in deze richting gedacht heeft. In het werk van Bolinger (1961, 1976), Becker (1984a, 1984b), en Hopper (1987), wordt een visie uiteengezet die zich nadrukkelijk distantieert van de formele grammatika's zoals we die kennen. Deze onderzoekers willen de konkrete taaldata centraal stellen; nieuwe uitingen worden opgebouwd uit brokstukken die aan eerder verwerkte teksten ontleend worden; idiomaticiteit is regel in plaats van uitzondering.
Deze onderzoekstraditie heeft geen grote nadruk gelegd op de formalisering van zijn ideeën. Sommige van deze onderzoekers suggereren zelfs dat zij hun perspektief op taal intrinsiek inkompatibel achten met formalisering; zij koncentreren zich volledig op informele, anekdotische beschrijving van zeer specifieke taalverschijnselen, zoals semi-idiomatische uitdrukkingen en konventionele zinswendingen. Als we ons daardoor niet van de wijs laten brengen, en toch willen proberen om dit soort ideeën in een formele richting uit te werken, vinden we het beste aanknopingspunt in het werk van Fillmore et al. [1988]. Daar wordt voorgesteld om een taal niet te beschrijven door middel van een verzameling herschrijfregels, maar door middel van een verzameling "konstrukties". Een konstruktie is een boomstruktuur: een fragment van een konstituenten-struktuur dat meer dan één niveau kan omvatten. Deze boom is gelabeld met syntaktische, semantische en pragmatische kategorieën en feature-waarden. Lexikale items kunnen als onderdeel van een konstruktie gespecificeerd zijn. Konstrukties kunnen idiomatisch van aard zijn: de betekenis van een grotere konstituent kan gespecificeerd worden zonder uit de betekenissen van sub-konstituenten opgebouwd te zijn.
Fillmore's ideeën verraden nog sterk de invloed van de traditie van formele grammatika's: de kombinatoriek van het "in elkaar schuiven" van konstrukties definieert een klasse van zinnen op een manier die erg lijkt op een kontekstvrije grammatika. De manier waarop Fillmore het grammatika-begrip veralgemeent lost echter wel precies het probleem op dat we aantroffen bij de huidige statistische grammatika's: als een "konstruktie-grammatika" gekombineerd wordt met statistische noties, is het wellicht wel mogelijk om alle gewenste statistische informatie weer te geven. Deze gedachte willen we nu verder uitwerken.
Het menselijke taal-interpretatie-proces heeft een sterke voorkeur voor het herkennen van zinnen, zinsdelen en patronen die reeds eerder zijn voorgekomen. Frekwenter voorgekomen strukturen en interpretaties woren bevoordeeld boven niet of zeldener waargenomen alternatieven. Alle lexikale elementen, syntaktische strukturen en "konstrukties" die de taalgebruiker ooit is tegengekomen, en hun frekwentie van voorkomen, kunnen een invloed hebben op de verwerking van nieuwe input. Het informatiebestand dat nodig is voor een realistisch performance-model is dus veel groter dan de grammatika's waaraan we gewend zijn. De taal-ervaring van een volwassen taalgebruiker bestaat uit een groot aantal uitingen. En elke uiting bevat een veelheid aan konstrukties: niet alleen de hele zin, en al zijn konstituenten, maar ook alle patronen die we daaruit kunnen abstraheren door "vrije variabelen" te introduceren voor lexikale elementen of complexe konstituenten.
Hoe al deze informatie, geannoteerd met voorkomensfrekwenties, voor een groot corpus weer te geven? In tegenstelling tot het menselijk brein, zijn de thans beschikbare computer-opslag-media niet ingesteld op onmiddellijke en flexibele associatieve toegang tot reusachtige gegevensbestanden. Voordat praktisch bruikbare systemen tot stand zouden kunnen komen, moeten er dus aanzienlijke implementatieproblemen worden opgelost. Maar als we de implementatieproblemen even terzijde laten, en ons concentreren op de specificatie van wat er geïmplementeerd moet worden, dan is de situatie heel eenvoudig. De informatie die nodig is, is een zo goed mogelijk model van de konkrete verleden taal-ervaring van de taalgebruiker. Dat wil zeggen: een zo groot mogelijk corpus van zinnen met hun syntaktische analyses en semantische interpretaties. Omdat alle voorkomende patronen, en hun frekwenties, van invloed kunnen zijn op de verwerking van nieuwe input, is er nauwelijks informatie in het corpus die veronachtzaamd kan worden. Conceptueel kunnen we er dus net zo goed van uit gaan, dat het taalverwerkingsproces de beschikking heeft over het gehele corpus.
Wanneer het taalverwerkingsproces de beschikking heeft over een representatie van de gehele verleden taal-ervaring van de taalgebruiker (of een voldoende groot sample daarvan), in de vorm van een corpus van zinnen met syntaktische analyse-bomen en semantische interpretaties, dan ontstaat de mogelijkheid voor een nieuw perspektief op parsering. Parsering hoeft nu niet te gebeuren door toepassing van grammatikale regels op de input-zin, maar kan bestaan uit een matching-proces dat tracht een optimale analogie te konstrueren tussen de input-zin en zoveel mogelijk corpus-zinnen. De aard van dit proces kan het best geïllustreerd worden aan de hand van twee extreme gevallen. Enerzijds kan een zin herkend worden omdat hij letterlijk in het corpus voorkomt; zo'n zin krijgt dan ook bij voorkeur dezelfde analyse als de betreffende corpus-zin. Anderzijds is het mogelijk dat het matching-proces allerlei corpus-zinnen in beschouwing moet nemen, en bij elk van die zinnen moet abstraheren van de meeste eigenschappen ervan; in zo'n geval is het systeem in feite bezig om naar aanleiding van de input-zin de relevante grammatika-regels "on the fly" uit het corpus te abstraheren. Meestal zal de input-zin een karakter hebben dat tussen deze beide extremen in ligt: er zijn wel zekere abstrakties nodig om een suksesvolle match te maken, maar sommige kombinaties van eigenschappen van de input-zin kwamen reeds in het corpus voor en kunnen als één geheel (een "konstruktie" à la Fillmore) in het matching-proces behandeld worden. Een typisch geval leidt dus tot een kombinatie van "domme" herkenning en gewone parsering.
Bij de gedetailleerde uitwerking van het matching-proces moeten twee randvoorwaarden goed in het oog gehouden worden:
(1) De analogie tussen de input en het corpus moet liefst op een zo eenvoudig mogelijke manier tot stand komen. De brokstukken en patronen uit de input-zin die in het corpus teruggevonden worden, moeten bij voorkeur elk een zo groot mogelijk gedeelte van de konstituenten-struktuur beslaan. Anders gezegd: het aantal konstrukties waaruit we de input-zin opgebouwd moeten denken om hem als herkend te kunnen bestempelen moet zo klein mogelijk zijn.
(2) De verrassende resultaten die bereikt zijn met eenvoudige statistische modellen vormen een belangrijke aanwijzing dat de frekwentie van voorkomen van de konstrukties in het corpus een rol moet spelen in het analyse-proces. Frekwentere konstrukties moeten geprefereerd worden boven minder frekwente. (Statistisch beschouwd, kan dit effekt op een elegante impliciete manier verkregen worden door "at random" in het corpus naar matchende konstrukties te zoeken!)
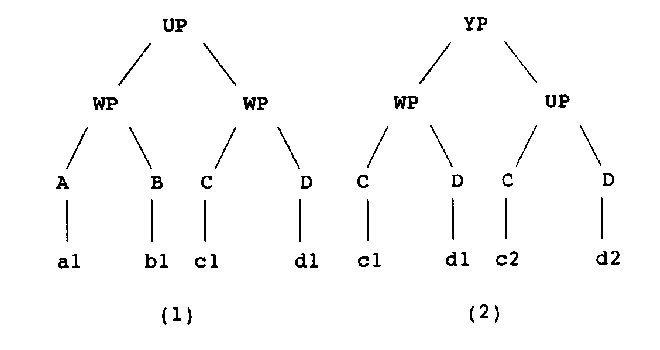
Tot slot een extreem eenvoudig formeel voorbeeldje zonder enige linguïstische inhoud, om het basis-idee duidelijk te maken. Neem aan dat het hele corpus slechts bestaat uit de volgende twee bomen:
Dan kan de input-string "c2 d2" als een UP herkend worden door letterlijke match met de UP-constituent in boom (2). Hij kan ook als een WP herkend worden door de regel WP => C + D die zowel in (1) als in (2) herkend kan worden, te kombineren met de regels C => c2 en D => d2, die uit (2) kunnen worden afgeleid. We achten deze laatste interpretatie onwaarschijnlijker, omdat hij pas in drie stappen tot stand komt.
Op dezelfde wijze zijn er twee mogelijkheden voor de analyse van de string "c1 d1". hij kan als WP gezien worden op grond van letterlijke herkenning in (1) en (2), en als UP door herschrijfregels voor UP, C en D te kombineren. Het feit dat de letterlijke herkenning van "c1 d1" als WP twee maal voorkomt in het corpus, en de benodigde herschrijfregel voor UP slechts éénmaal, doet in dit geval de balans nog duidelijker uitslaan in de richting van de analyse die door eenvoudige herkenning tot stand komt.
De analyse is iets complexer in het volgende geval. De string "c1 d1 a1 b1 a1 b1" wordt als een YP geanalyseerd door kombinatie van de volgende konstrukties uit het corpus:

die afkomstig zijn uit respektievelijk boom (2), boom (1) en boom (1). Dit geval illustreert dat "konstrukties" à la Fillmore, net als kontekstvrije herschrijfregels, op een rekursieve manier toegepast kunnen worden in het matching-proces.
7. Theoretische gevolgen van de voorgestelde benadering.
De hier voorgestelde parseer-technologie impliceert een perspektief op taalbeschrijving dat op essentiële punten verschilt van het tot nu toe gebruikelijke. Ik zal nu wat verder ingaan op enkele theoretisch interessante gevolgen van dit nieuwe perspektief.
1.
Het onderscheid tussen grammatikale en ongrammatikale zinnen verliest zijn absolute karakter. Dit mag op het eerste gezicht onaantrekkelijk lijken, in een taalkundige traditie die gegrondvest is op Chomsky's definitie van een formele grammatika als een rekursieve karakterisering van precies alle grammaticale zinnen van een taal. Maar in feite sluit het aan op een ontwikkeling die in de theoretische linguistische discussies al enige tijd aan de gang is. Deze discussies gaan vaak over interacties tussen complexe verschijnselen, die geïllustreerd worden door zodanig ingewikkelde taaluitingen dat zelfs de professionele taalkundige het moeilijk vindt om er nog absolute grammaticaliteitsoordelen over te hebben. In plaats daarvan spreekt men daarom relatieve grammaticaliteitsoordelen uit: zinnen worden niet als wel of niet grammaticaal gekategoriseerd, maar worden ten opzichte van elkaar geordend als zijnde meer of minder grammaticaal. Dit betekent dat men aanneemt dat een taal niet één grammatica heeft (in de Chomskyaanse zin des woords), maar een multipliciteit van grammatica's waarover een partiële ordening is gedefinieerd. Deze aanname blijft meestal impliciet, en geïmplementeerde systemen gebruiken meestal nog steeds één grammatica.
De verwachting is, dat in het hier voorgesteld procesmodel de meest plausibele zinnen met weinig moeite geanalyseerd kunnen worden, en dat de analyse van ongewonere en minder grammaticale zinnen aanzienlijk meer verwerkingstijd kost. We hopen dat het mogelijk zal zijn om de "relatieve grammaticaliteit" die aldus uit een verwerkingsmodel volgt, in overeenstemming te brengen met linguistische relatieve grammaticaliteitsoordelen.
2.
Een hiermee samenhangend verschijnsel is, dat menselijke grammaticaliteitsoordelen niet stabiel zijn. Of een zin als grammaticaal beschouwd wordt, hangt vaak af van de context waarin hij aangeboden wordt -- van zijn semantisch/pragmatische plausibiliteit, maar ook van de struktuur van voorafgegane zinnen. Matthews (1979) argumenteert dat grammaticaliteit wellicht geen beslisbare eigenschap van zinnen is. Hij geeft voorbeelden van het zojuist genoemde verschijnsel: een zin met een bepaalde struktuur stelt de taalgebruiker soms in staat om in een volgende zin een analoge struktuur te herkennen, die hij zonder deze "priming" niet had kunnen waarnemen. Dit verschijnsel is absoluut incompatibel met de standaard parseermethodes die uitsluitend met grammatica-regels werken. In de data-georiënteerde benadering die we voorstellen past het echter heel goed: als recente uitingen zwaarder meetellen in het matching-proces, ontstaat zo'n bias onmiddellijk.
Onze verantwoording van grammaticaliteitsoordelen ligt dus in de lijn die gesuggereerd wordt door Stich (1971). Grammaticaliteitsoordelen komen niet tot stand door de toepassing van een geprecompileerde verzameling grammaticale regels, maar hebben veeleer het karakter van een perceptief oordeel over de vraag, in welke mate de beoordeelde zin "lijkt op" de zinnen die de taalgebruiker als voorbeelden van grammaticaliteit in zijn hoofd heeft. De konkrete taal-ervaringen uit het verleden van de taalgebruiker bepalen hoe hij een nieuwe uiting verwerkt; en er is geen evidentie voor de aanname dat de verleden taal-ervaringen veralgemeend zijn tot een consistente theorie die de grammaticaliteit en de struktuur van nieuwe uitingen eenduidig defineert.
3.
Het voorgestelde onderzoek stelt het paradigma van Saussure ter discussie, dat het linguistische onderzoek de laatste decennia volledig gedomineerd heeft. "Saussure's originality was to have insisted on the fact that language as a total system is complete at every moment, no matter what happens to have been altered in it a moment before". (Jameson, 1972). De aanname van een consistent, volledig systeem, die een van de pijlers vormt van Chomsky's traditie in syntax en van Montague's traditie in semantiek, wordt door ons onderzoek in twijfel getrokken. Doordat we de konkrete taaldata centraal stellen, wordt het consistente algebraische taalsysteem een epifenomeen, dat ook kan blijken grotendeels illusoir te zijn. Het is heel wel mogelijk dat de taal een conglomeraat van incompatibele maar overlappende "subsystemen" is, dat ook op vele punten ongedetermineerd is.
4.
Door Saussure's paradigma ter discussie te stellen, worden nieuwe wegen geopend naar een formele verantwoording van het proces van taalverandering -- iets dat moeilijk is in benaderingen die de taal willen zien als een op ieder moment consistent en volledig mathematisch systeem. "L'opposition synchronie/diachronie se situant à l'interieur de la langue, le changement est, chez F. de Saussure, le lieu d'un paradoxe: c'est par des actes de parole que la langue change". (Robert, 1977)
5.
Een soortgelijke paradox heeft Fodor (1975) aan het licht gebracht m.b.t. de taalverwerving van het individu: wanneer de menselijke linguïstische cognitie op elk moment beschreven kan worden als een consistent computationeel systeem dat berekeningen doet op mathematisch welgedefinieerde "representaties", dan wordt het heel raadselachtig hoe iemand ooit een "echt nieuw" concept kan leren: alle concepten die iemand ooit in zijn denken kan gebruiken moeten reeds gegenereerd kunnen worden door de algebra van elementaire concepten en operaties van iemands "language of thought". Fodor laat zien dat deze vooronderstellingen impliceren dat iemands conceptuele repertoire volledig is "aangeboren". Verrassend genoeg, accepteert hij deze absurde conclusie.
De absurditeit van Fodor's standpunt wordt de laatste jaren in steeds bredere kring ingezien, en er is zelfs een zekere eenstemmigheid aan het ontstaan over het antwoord op de "Fodor-paradox": we moeten het gaan hebben over "subsymbolische processen": berekeningen op niet-symbolische data, in plaats van berekeningen op symbolische representaties. De onderliggende gedachte is, dat het cognitieve systeem niet "echt" met symbolische representaties werkt. De symbolen zijn slechts "emergent phenomena".
Tot nog toe is het idee van een subsymbolische verantwoording van taalverwerking vooral uitgewerkt in termen van "connectionistische" (neurologisch geïnspireerde) modellen (zie b.v. Rumelhart et al. (1986), McClelland et al. (1986)). Daarmee wordt aan dit idee niet volledig recht gedaan. De capaciteiten van connectionistische netwerken zijn beperkt; het is nog allerminst duidelijk hoe andere taken dan eenvoudige classificaties in een n-dimensionale ruimte er goed op kunnen worden uitgevoerd. De resultaten zijn dus bescheiden, en kunnen gemakkelijk bekritiseerd worden. (Zie b.v. Pinker & Mehler (1988), Levelt (1989).).
Het connectionistische onderzoeksprogramma vereenzelvigt twee verschillende onderzoeksdoelen. In de eerste plaats streeft men de uitwerking na van enkele alleszins plausibele ideeën over het statistische, data-georiënteerde karakter van taalverwerking en andere cognitieve aktiviteiten. In de tweede plaats legt men zich vast op een implementatie van deze statistische processen op een heel specifiek soort gedistribueerde hardware-architektuur (connectionistische netwerken). De onderliggende veronderstelling is, dat de operatie van connectionistische netwerken een zinvolle idealisering vormt van de elementaire processen die in het menselijk brein de menselijke cognitie implementeren; bij deze veronderstelling zijn echter talrijke vraagtekens te plaatsen. Daarom doet taalkundig onderzoek dat zich vastlegt op deze interessante maar erg moeilijke implementatie-omgeving, geen recht aan het potentieel van het statistische perspektief op cognitie, dat data en perceptie benadrukt in plaats van regels en redenering.
Het is misschien een van de belangrijkste verdiensten van de hier voorgestelde aanpak dat hij veel eigenschappen gemeen heeft met de connectionistische benadering, maar dat hij uitgaat van een krachtiger en flexibeler computationeel kader. Net als de proponenten van de neurale netwerken, proberen we de verwerking van een nieuwe uiting te verklaren als een gevolg van de integratie van deze uiting met de som van alle eerder opgeslagen uitingen; we vermijden om een beroep te doen op expliciet opgeslagen abstrakte regels. Maar we staan toe dat de linguïstische struktuur van de opgeslagen taal-uitingen een rol speelt in het proces. En we leggen geen enkele beperking op aan de aard en de complexiteit van het matching-proces, dat zich afspeelt bij het verwerken van een nieuwe uiting.
8. Konklusies en verder onderzoek.
Het bovenstaande laat zien, dat ideeën die hun oorsprong hebben in de taaltechnologische problematiek, interessant kunnen zijn voor de taalkundige theorie. Het bovenstaande laat echter nog niet zien, dat deze ideeën ook inderdaad korrekt zijn. Om ze uit te werken en te valideren, is nog veel onderzoek nodig. Ik ga nu kort in op de onderzoeksvragen die hier worden opgeroepen.
1.
Op de allereerste plaats is het nodig om het hierboven impressionistisch geschetste matching-algoritme in detail te specificeren, en de eigenschappen ervan in de praktijk te toetsen. Het zal vooral interessant zijn om vast te stellen hoe zulk een algoritme om kan gaan met complexe syntaktische verschijnselen, zoals "long distance movement". Het is heel goed voorstelbaar dat een optimaal matching-algoritme niet uitsluitend opereert op konstrukties die expliciet in de oppervlakte-struktuur aanwezig zijn; wellicht spelen "transformaties" (in de klassieke Chomskyaanse zin) een rol in het parseerproces.
Om de technologische bruikbaarheid van het matching-algoritme aan te tonen, moeten de desambiguerende capaciteiten van het algoritme vergeleken worden met die van de reeds bestaande methoden: de kombinatie van een konventionele grammatika met ne orde Markov-waarschijnlijkheden; en de probabilistische contekstvrije grammatika's waar reeds bemoedigende resultaten mee geboekt zijn. [Fusijaki et al., 1989]
2.
Er zijn enkele vragen over de status van de hierboven geschetste ideeën in de contekst van de Theorie der Formele Talen, die expliciete bestudering verdienen. In de eerste plaats is het niet a priori duidelijk of de hierboven aangeduide matching-algoritmes formele talen definiëren die (afgezien van de plausibiliteits-ordening tussen verschillende strukturen) in principe ook door middel van reeds bekende grammaticale formalismes gedefinieerd zouden kunnen worden, en zo ja, door welke daarvan. Verder kan men zich ook afvragen of er sterkere equivalentie-relaties vast te stellen zijn: is het wellicht bewijsbaar dat de toepassing van een matching-algoritme op een corpus dat gegenereerd werd door een bepaalde grammatica, ook weer dezelfde analyses voor input-zinnen oplevert die door de grammatica gedefinieerd werden?
Omdat matching-algoritmen verzamelingen zinnen definiëren met (partiële) ordeningen daarover gespecificeerd (en dat wellicht op een non-deterministische manier), kan men eraan denken om de Theorie der Formele Talen uit te gaan breiden op een manier die deze aspekten, die tot nog toe buiten het bereik van de Mathematische Linguistiek vallen, in de beschouwing betrekt.
3.
De hier geschetste ideeën zijn van eminent belang voor de psycholinguïstiek. Ondanks Chomsky's waarschuwende woorden over het abstrakte karakter van zijn taaltheorie, zijn in de psychologie steeds weer de regelsystemen van de taalkunde als "psychologisch reëel" geïnterpreteerd. Data-georiënteerde parsering is psychologisch veel plausibeler, omdat het niet abstrakte regels als uitgangspunt neemt, maar konkrete taalervaringen. Dit heeft b.v. interessante konsekwenties voor de taalverwerving. Omdat er geen abstrakte grammatika gecompileerd hoeft te worden, ontstaat er volledige kontinuïteit tussen de vroege stadia van taalgebruik en de latere stadia van taalgebruik. Er hoeft geen afzonderlijk proces van taalverwerving gepostuleerd te worden. Wel doet zich een belangrijke vraag voor over de aard van het vroege taalgebruik: hoe werkt ons matching-algoritme als er nog geen corpus is? Deze vraag brengt op een heel duidelijke manier de niet-linguistische komponent van de taalverwerking in het vizier: de semantisch/pragmatische kontekst die we op een of andere manier op de linguistische input proberen te projekteren. In de vroege stadia van taalgebruik moet deze komponent duidelijk de overheersende zijn -- later wordt de linguistische steeds prominenter. (Daarom kunnen volwassen taalgebruikers "grammatikaliteitsoordelen" hebben over "voorbeeldzinnetjes" zonder kontekst. Bij beginnende taalgebruikers zou dat niet mogelijk zijn.)
Het hier ontwikkelde model levert voor het eerst de mogelijkheid voor een plausibel model van het taalverwervingsproces: de geleidelijke ontwikkeling van de linguistische komponent van de taalverwerking, door de geleidelijke toename van het repertoire van, geleidelijk aan ook complexere, linguistische ervaringen. Om op een gedetailleerde manier te beschrijven hoe de vroege, semantisch/pragmatisch georiënteerde stadia van het taalgebruik verlopen, en hoe de linguistische komponent zich daaruit ontwikkelt, zal toch zeker niet eenvoudig zijn.
4.
Het is een interessante eigenschap van de hier voorgestelde taalverwerkingsprocessen, dat ze waarschijnlijk veel "robuuster" zijn dan de huidige taalverwerkingstechnieken. De verwachting is dat ze beter bestand zijn tegen fouten in de input, d.w.z., dat ze bij input die fouten bevat toch nog een gok kunnen doen naar de gewenste analyse, en het niet helemaal hoeven te laten afweten. We kunnen met doelgerichte experimenten de robuustheid van een matching-algoritme vaststellen, door een corpus te genereren op basis van een formele grammatika, en dat met "ruis" (willekeurige variaties) te corrumperen. Vervolgens kunnen we dan vaststellen in welke mate het matching-algoritme toch korrekte analyses oplevert.
Robuustheid is praktisch belangrijk, omdat kleine typ-fouten en ongrammatikaliteiten vaak optreden bij interaktieve alphanumerieke computer-input, en ook omdat de karakterisering van de te verwachten invoer die het systeem hanteert (of het nu een grammatika of een corpus is) altijd ongewenste beperkingen zal hebben. Bij de verwerking van gesproken taal doen zulke problemen zich nog in versterkte mate voor.
5.
De hier geschetste benadering zal idealiter leiden tot matching-algoritmen die bewijsbaar optimale analyses van hun input opleveren. Maar dat resultaat krijgen we niet cadeau. Dat wordt verkregen op grond van een hoeveelheid rekenwerk die met bestaande apparatuur misschien nauwelijks te realiseren is. Om praktisch nut te hebben van de te verwachten resultaten, zal het probleem van de implementatie van geannoteerde corpora en matching-algoritmen onder ogen gezien moeten worden.
In eerste instantie zal men zich bezig moeten houden met efficiënte implementatie op bestaande hardware. Om werkelijk grootschalige toepassing van de ontwikkelde technieken mogelijk te maken, zal wellicht de ontwikkeling van speciale hardware nodig zijn.
9. Referenties.
L.B. Bahl, F. Jelinek, en R.L. Mercer: A maximum likelihood approach to continuous speech recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. PAMI-5, No.2, maart 1983.
A.L. Becker: Biography of a sentence: a Burmese proverb. In: E.M. Bruner (red.): Text, play, and story: The construction and reconstruction of self and society. Washington, D.C.: American Ethnology Society, 1984a. Pp. 135-155.
A.L. Becker: The linguistics of particularity: Interpreting superordination in a Javanese text. Proceedings of the Tenth Annual Meeting of the Berkeley Linguistics Society, pp. 425-436. Berkeley, Cal.: Linguistics Department, University of California at Berkeley, 1984b.
S.Boisen, Y. Chow, A. Haas, R. Ingria, S. Roukos, R. Scha, D. Stallard, en M. Vilain: Integration of Speech and Natural Language. Final Report. BBN Systems and Technologies Corporation, Cambridge, Mass. Report no. 6991, maart 1989.
D. Bolinger: Syntactic blends and other matters. Language 37, 3 (1961), pp. 366-381.
D. Bolinger: Meaning and Memory. Forum Linguisticum 1, 1 (1976), pp. 1-14.
N. Chomsky: Syntactic Structures. The Hague: Mouton, 1957.
Derouault, A.M. and B. Merialdo: Natural language modeling for phoneme-to-text transcription. IEEE Trans. PAMI, 1986.
C.J. Fillmore, P. Kay, and M.C. O'Connor: Regularity and idiomaticity in grammatical constructions. Language, 64, 3 (1988)
J.A. Fodor: The language of thought. New York: T.Y. Crowell, 1975.
T. Fusijaki: A stochastic approach to sentence parsing. Proc. 10th International Conference on Computational Linguistics. Stanford, CA, 1984.
T. Fusijaki, F. Jelinek, J. Cocke, E. Black, and T. Nishino: A Probabilistic Parsing Method for Sentence Disambiguation. Proc. International Parsing Workshop '89. Pittsburgh: Carnegie-Mellon University, 1989. Pp. 85-94.
P. Hopper: Emergent Grammar. Proceedings of the 13th Annual Meeting of the Berkeley Linguistics Society. Berkeley, Cal.: Linguistics Department, University of California at Berkeley, 1987.
F. Jameson: The prison-house of language: A critical account of structuralism and Russian Formalism. Princeton and Londen: Princeton University Press, 1972.
F.Jelinek: Self-organized language modeling for speech recognition. Ms., IBM T.J. Watson Research Center, Yorktown Heights, N.Y., 1986.
W.J.M. Levelt: De connectionistische mode. Symbolische en subsymbolische modellen van het menselijk gedrag. In: C. Brown, P. Hagoort, en Th. Meijering (red.): Vensters op de geest. Cognitie op het snijvlak van filosofie en psychologie. Utrecht: Stichting Grafiet, 1989. Pp. 202-219.
R.J. Matthews: Are the grammatical sentences of a language a recursive set? Synthese 40 (1979), pp. 209-224.
J.L. McClelland, D.E. Rumelhart, and the PDP Research Group: Parallel Distributed Processing: Explorations in the microstructure of cognition. Volume 2: Psychological and biological models. Cambridge, Mass.: MIT Press, 1986.
S. Pinker en J. Mehler (red.): Connections and Symbols. Cambridge, Mass.: MIT Press, 1988.
F. Robert: La langue. In: D. Causset et al.: La Linguistique. Parijs: Librairie Larousse, 1977.
D.E. Rumelhart, J.L. McClelland, and the PDP Research Group: Parallel Distributed Processing: Explorations in the microstructure of cognition. Volume 1: Foundations. Cambridge, Mass.: MIT Press, 1986.
S.P. Stich: What every speaker knows. Philosophical Review, 1971.